Modular Application Architecture - Pipelines
When developing software, sometimes we need to allow our application to have plug-ins or modules developed by third parties. In this post we will see in which contexts "pipelines" can be used as plugin mechanism.

This is the third post from a series of posts that will describe strategies to build modular and extensible applications. In this post we will start looking on how to implement a plugin-system by using "pipelines". Some implementations calls them "middleware".
The approach of pipelines if compared to events is used in a different context. Events are used more often in contexts where is necessary to add functionalities (changing existing functionalities is possible only if the event-type supports it). Pipelines on the other hand are used when in addition to adding new data is useful also to allow altering existing data.
Generally speaking, with "pipelines" we have simply some data going through a series of transformations.
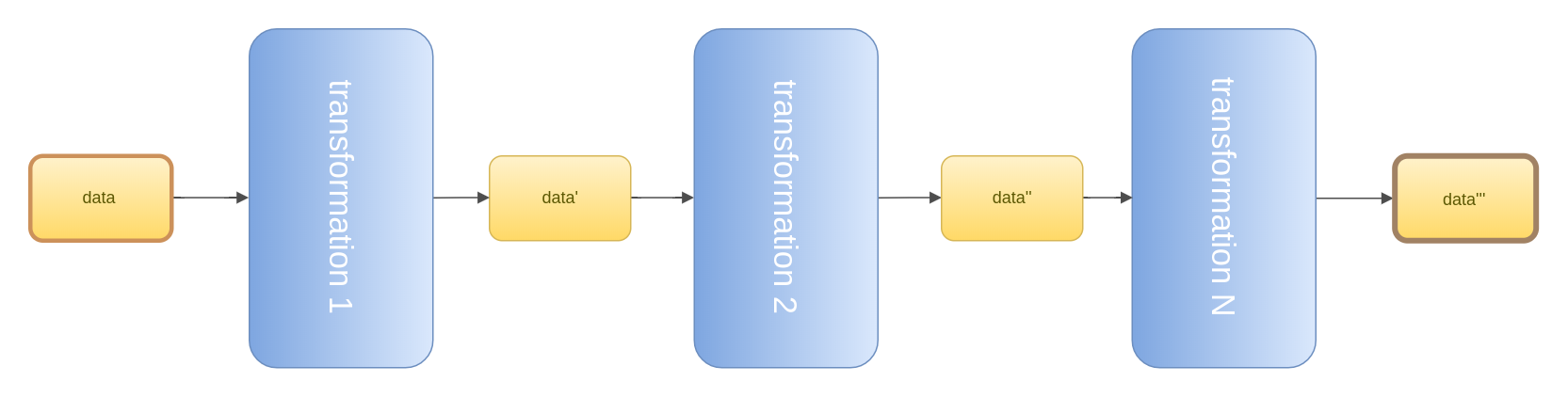
Some implementations allows you to decide the order of execution, some do not, some allows you also to change the order at runtime.
As the execution order might be important, the "plugin registration" step is very important (see the first post for more info about it).
Use case
A great example of pipelines are the PSR-7 middlewares (here a good post about it), where each "plugin" can alter an HTTP message by adding as example HTTP cookies, Credentials, Compression, Caching headers and so on. As example, adding a cookie can be considered as adding1 a functionality, but as example compressing the HTTP message means most probably replacing the old message with a new and compressed one.
Note 1: currently PSR-7 is immutable so we are always replacing the old object with a new one.
Text processing can be also a pretty common use case, as example, if we want to extract only "important" words from a text. We could have steps that performs tokenization, removal of stopwords, stemming and verbs/nouns extraction.
Another use of the pipelines can be image processing. Let's suppose we want to allow a user upload a picture that needs to be stored. The image probably should be resized, have applied a watermark and compressed for storage. This are 3 independent steps and probably are useful in different cases. As example: - "watermarking" step can be used also for the profile picture, - "resizing" can be used probably in many other cases where is necessary to resize an image.
"compression" can be more delicate as it might compress the image as ".zip", ant the other transformations should be able to deal with that type of data.
This step puts us in front of one of drawbacks of this plugin system. The "datatype" that is going through the pipeline should be known to the transformer in order to allow it to apply some transformation, but the concept of pipelines is the "altering" of the datatype on each step.
Implementations
Different needs have different implementations, this mostly because of the different data-types that we might be interested in processing.
In the following examples, each implementation works on a different data-type so it might look different from the other.
The PHP League Pipeline
The PHP League Pipeline aims to be a independent library to implement pipelines.
The implementation is more "pure" compared to other, the "data" are always replaced with the new one on each step (immutability). Steps can't block the processing or later the execution order.
A basic example can be:
<?php
class MultiplyTwoStage
{
public function __invoke($payload)
{
return $payload * 2;
}
}
class AddOneStage
{
public function __invoke($payload)
{
return $payload + 1;
}
}
Registration
The Pipeline implementation is bare minimum, and the registration is fully manual.
Order execution needs to be explicitly configured.
<?php
use League\Pipeline\Pipeline;
$pipeline = (new Pipeline)
->pipe(new MultiplyTwoStage)
->pipe(new AddOneStage);
// run the pipeline
$pipeline->process(10); // Returns 21
As you can see, the Pipeline makes no assumption on the data and is bare minimum.
Laravel
The laravel middleware strategy is heavily used as plugin system for it.
Most of the request-response cycle in laravel is handled by it. Different "plugins" can add them self to the pipeline and perform some operations to the final HTTP message that will be delivered to the user.
As plugins in this case we have anything that might be interested to interact with the HTTP request.
Laravel middlewares are able to: modify the HTTP message, replace it, change the pipeline order or even to stop the pipeline processing.
Let's see how it works:
<?php
use Closure;
class CheckIp
{
public function handle($request, Closure $next)
{
if ($request->getClientIp() === '1.2.3.4') {
return redirect('/not-allowed');
}
return $next($request);
}
}
This is one example transformer.
If the user's IP is in a blacklist, redirects it to a specific page (redirect('/not-allowed')), otherwise
allows the pipeline processing to continue $next($request).
In this case the CheckIp transformers acts "before" the "next" step. In case of a not-authorized user,
it stops the pipeline processing.
Another example can be
<?php
use Closure;
class CompressResponse
{
public function handle($request, Closure $next)
{
$response = $next($request);
$response->setContent(gzcompress($response->getContent()));
$response->headers->set("Content-Encoding", "gzip");
return $next($request);
}
}
In this example we are letting the pipeline continue the flow, and at the end we compress the response.
In this case the CompressResponse transformers acts "after" the "next" step.
Registration
As plugin registration mechanism, laravel uses explicit configuration, by using an array of middlewares. It is a simple but powerful enough mechanism to deal with it. The developer can choose which middleware use and in which order execute them.
Laravel middleware registration.
<?php
protected $routeMiddleware = [
'auth' => \Illuminate\Auth\Middleware\Authenticate::class,
'auth.basic' => \Illuminate\Auth\Middleware\AuthenticateWithBasicAuth::class,
'bindings' => \Illuminate\Routing\Middleware\SubstituteBindings::class,
'can' => \Illuminate\Auth\Middleware\Authorize::class,
'guest' => \App\Http\Middleware\RedirectIfAuthenticated::class,
'throttle' => \Illuminate\Routing\Middleware\ThrottleRequests::class,
];
Laravel offers also a way to register middlewares acting ony on a specific url/route, but this is already an implementation detail.
Gulp
Gulp is a javascript build tool.
Is based on the concept that a series of files go through a series of transformations and produce some result
(most of the times some .js or .css files).
As plugins in this case we have the possible transformers for those files.
var gulp = require('gulp');
var less = require('gulp-less');
var minifyCSS = require('gulp-csso');
gulp.task('css', function () {
return gulp.src('client/templates/*.less') // get all the *.less files inside the client/templates folder
.pipe(less()) // process *.less files
.pipe(minifyCSS()) // compress them
.pipe(gulp.dest('build/css')) // write the result to the build/css folder
});
To run this "task" you will have to run in your console something as gulp css.
This example is relatively simple. A task named css has been created.
As "data" we are using the *.less files inside the client/templates folder; the data are going through the less
transformer (that converts them to CSS), then the data are going to minifyCSS that reduces the size of the CSS;
in the end data are written to the build/css folder.
More implementations?
As the data that we might be working with can be really different, the list of possible implementations is too long to be discussed here. Just as example, this is just a list of pipeline-based tools in the sys-admin area. Pretty big, right?
Conclusion
The pipeline approach is useful to filter/edit data by using a series of transformers/filters. Adding/Editing data can be relatively easy if the data structure we are working on supports it explicitly (as example HTTP headers), but when it comes to e adding/editing something in a data structure that does not support it out of the box (HTTP body) things can become more challenging. A key factor for the pipeline to work well is to have a convenient data structure.
Advantages:
- Transformers can follow strictly the "single responsibility principle"
- Simple architecture (it is just data going through transformations)
- Transformers can become really re-usable
- Very convenient for small changes
Disadvantages:
- Transformers can break the data
- Transformers have to understand well the data
- Linear flow (can't re process easily, things happen in a pre-defined sequence... that might not work for some cases)
- (If the implementation allows to change the execution order or to stop processing, things can go out of control and debugging can be hard)
The "pipeline" way of making plugins is simple and powerful, but has very specific use cases.
Hope you enjoyed this article and if you have some feedback, do not hesitate to leave a comment.